
в базах данных необходим поиск
Чаще всего в базах данных необходим поиск по первичному или возможному ключам, иногда необходима выборка по внешним ключам, но во всех этих случаях мы знаем значение ключа, но не знаем номера записи, который соответствует этому ключу.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер записи файла).
NZ = F(K),
где NZ — номер записи, К — значение ключа, F( ) — функция.
Функция F() при этом должна быть линейной, чтобы обеспечивать однозначное соответствие (см. рис. 9.5).
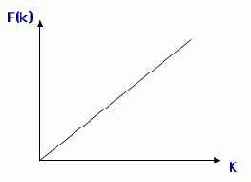
Рис. 9.5. Пример линейной функции пересчета значения ключа в номер записи
Однако далеко не всегда удастся построить взаимно-однозначное соответствие между значениями ключа и номерами записей.
Часто бывает, что значения ключей разбросаны по нескольким диапазонам (см. рис. 9.6).
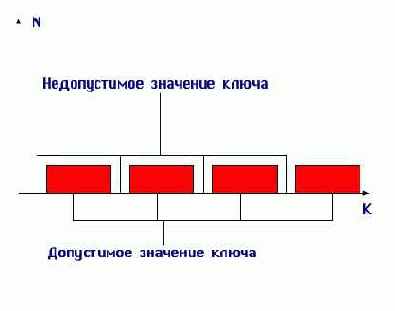
Рис. 9.6. Допустимые значения ключа
В этом случае не удается построить взаимнооднозначную функцию, либо эта функция будет иметь множество незадействованных значений, которые соответствуют недопустимым значениям ключа. В подобных случаях применяют различные методы хэширования (рандомизации) и создают специальные хэш- функции.
Суть методов хэширования состоит в том, что мы берем значения ключа ( или некоторые его характеристики) и используем его для начала поиска, то есть мы вычисляем некоторую хэш-функцию h(k) и полученное значение берем в качестве адреса начала поиска. То есть мы не требуем полного взаимно-однозначного соответствия, но, с другой стороны, для повышения скорости мы ограничиваем время этого поиска (количество дополнительных шагов) для окончательного получения адреса. Таким образом, мы допускаем, что нескольким разным ключам может соответствовать одно значение хэш-функции (то есть один адрес). Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хэш-функции, называются синонимами.
Поэтому при использовании хэширования как метода доступа необходимо принять два независимых решения:
Существует множество различных стратегий разрешения коллизий, но мы для примера рассмотрим две достаточно распространенные.