
Раздел GROUP BY CUBE
Наконец, заметим, что, в отличие от запросов с традиционной группировкой, результат запроса, содержащего раздел GROUP BY ROLLUP, зависит от порядка столбцов в списке группировки. При выполнении запроса происходит движение по этому списку слева направо с повышением уровня детальности результирующих данных. Существует еще одна разновидность запроса с группировкой, основанная на использовании раздела GROUP BY CUBE.
Пусть раздел группировки запроса имеет вид GROUP BY CUBE (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) - имя столбца таблицы-результата раздела FROM запроса. Обозначим через SGBC множество {cname1, cname2, ... , cnamen}. Пусть Si является произвольным подмножеством SGBC, т.е. Si представляет собой пустое множество или имеет вид {cnamei1, cnamei2, ... , cnameim}, где m



SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY CUBE (DEPT_NO, EMP_BDATE);
Пример 16.2. Найти максимальный размер зарплаты во всем предприятии, максимальный размер зарплаты в каждом отделе, максимальный размер зарплаты сотрудников в каждой возрастной категории и максимальный размер зарплаты сотрудников каждой возрастной категории каждого отдела. (html, txt)
Результирующая таблица для этого запроса будет иметь следующий вид:
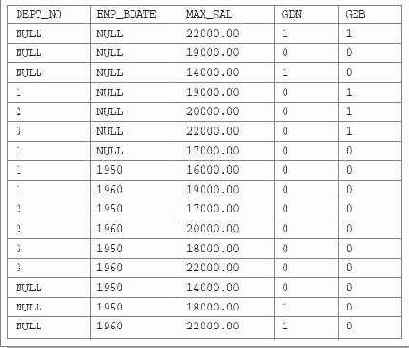
Рис. 16.4. Результат запроса с разделом GROUP BY CUBE и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Как видно, результат запроса из примера 16.2 совсем немного отличается от результата запроса из примера 16.1a. Добавились две последние строки, показывающие максимальные значения зарплаты всех сотрудников предприятия, родившихся в 1950-м и 1960-м гг. соответственно.
Наш пример может навести на мысль, что и в общем случае запросы, содержащие раздел GROUP BY CUBE, не слишком отличаются от запросов с GROUP BY ROLLUP, и выполнение этих запросов тоже не слишком различается. Однако это совсем не так. Запрос, содержащий раздел GROUP BY CUBE, действительно вырождается в объединение результатов 2n запросов с обычным разделом GROUP BY. Соответственно, сложность выполнения такого запроса несравненно выше сложности выполнения похожего запроса с GROUP BY ROLLUP. В нашем примере все получилось так просто только по той причине, что в запросе имеются всего два столбца группировки.